SOA - next: Integrated software and knowledge
engineering – a platform for developing intelligent systems
Presented at Pacific Northwest National Laboratory (PNL), Richmond, WA
by Jeff Zhuk
Did you dream about a
new development paradigm that can:
- Streamline the
transformation of ideas into applications.
- Give business experts
the keys to development.
- Allow new
conditions to change application rules at run-time.
- Introduce a new
world of applications that can inherit and learn rules, events, and
scenarios.
Current
advances in knowledge technologies combined with service-oriented architecture
are getting ready to solve a fundamental problem of application development:
changing the development process to give subject matter experts more control by
elevating business scenarios from application code, and thus opening up a
new world of applications that can adapt to multiple rules and learn new
conditions.
The article describes the background of the evolution in
the architecture and development of software systems, focuses on the integrated
software and knowledge engineering approach, and elaborates on practical
implications and implementation strategies.
Armed with Service-Oriented Architecture (SOA) and Web services, the software industry seems to be moving at a fast pace. However, some of the foundations of the field have stayed static for a long time.
The way we write software has not changed over the past twenty years. We have not moved far from the UNIX operational environment (which was a big hit thirty years ago). We write and re-write the same types of services and applications: orders, inventories, schedules, and games. We add power to computers, but fail to add common sense; we cannot help computers learn, and we routinely lose professional knowledge gained by millions of knowledge workers.
Most current implementations of Business Intelligence (BI) applications focus on smart data processing, reporting, and business analysis, such as creating document summaries or extracting useful information from reams of data.
However, current advances in knowledge technologies combined with service-oriented architecture can solve the even more fundamental problem of application development itself by streamlining the development process to open up a new world of applications that can adapt to multiple rules and learn new conditions.
Here is a summary of this integrated approach:
Objectives:
- Streamline the transformation of ideas into applications.
- Give Subject Matter Experts (SME) the keys to development.
- Allow new conditions to change application rules when necessary at run-time.
- Introduce a new world of applications that can inherit and learn rules, events, and scenarios.
Background and the Evolution of Software Development:
|
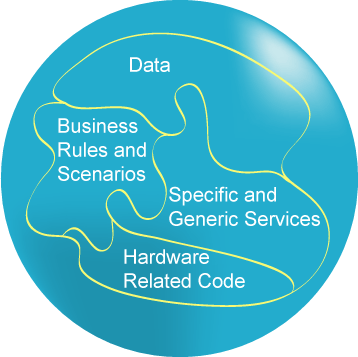
Some of us still remember a time when a single program could include video and disk drivers as well as data storage functionality mixed with application-specific code.
Fig.1.Software evolution |
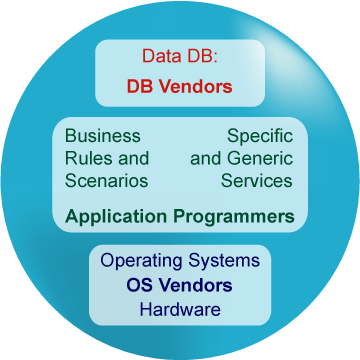
A new paradigm was created when database (DB) and operating system (OS) vendors took part in the process, and most software developers could focus on the application layer.
Fig.2. Software evolution |
|
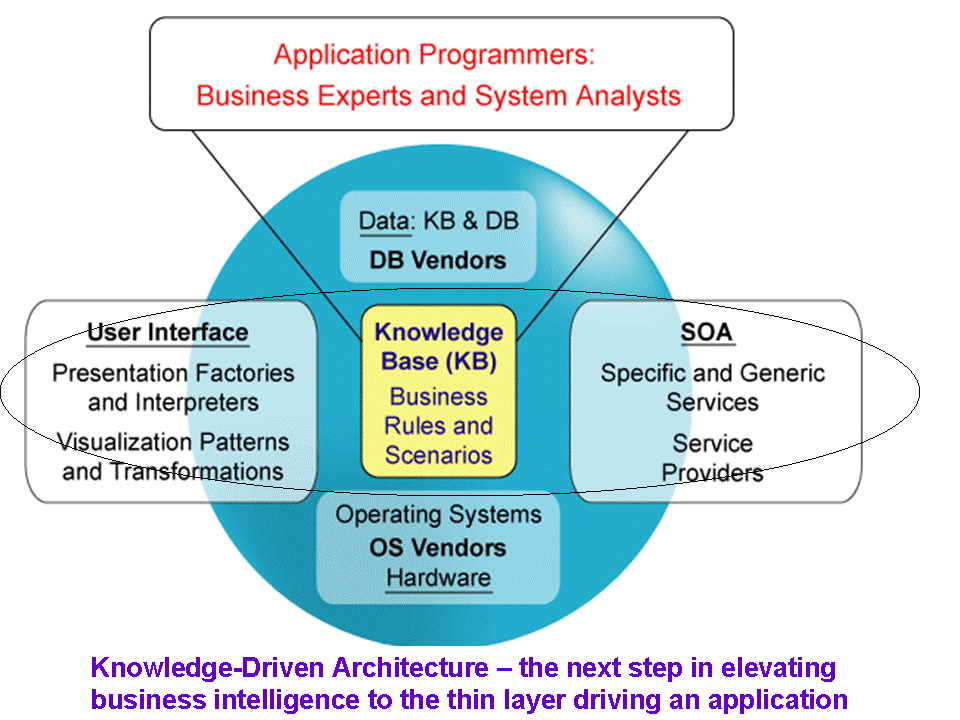
Today, the application layer continues to consist of a mixture of generic services and business specifics. Service-oriented and data-driven architectures, rules engines, and similar approaches help us clear this mess.
Fig.3. Software evolution |
|
Current advances in software and knowledge engineering have now paved the way for the further elevation of application business logics to the level where business rules and scenarios can be placed in standard containers to directly drive applications.
Fig.4. Software evolution |
The new approach is based on three major factors:
1. Intelligent enterprise systems require new mechanisms, architecture, and implementation methods that can be described as distributed knowledge technologies [1] and are based on integrated software and knowledge engineering.
2. Service-oriented architecture, web services and related developments have allowed us to free service descriptions and service invocations from service implementation details. We can combine in application scenarios business logics and service invocations with rich ontology expressions supported by knowledgebase containers.
3. Knowledgebase containers are not just a pipe dream – they are quite real, like the OpenCyc product from Cyc Corporation [2]. With time knowledgebase containers will become common components (similar to existing data storage platforms) in knowledge-driven architecture.
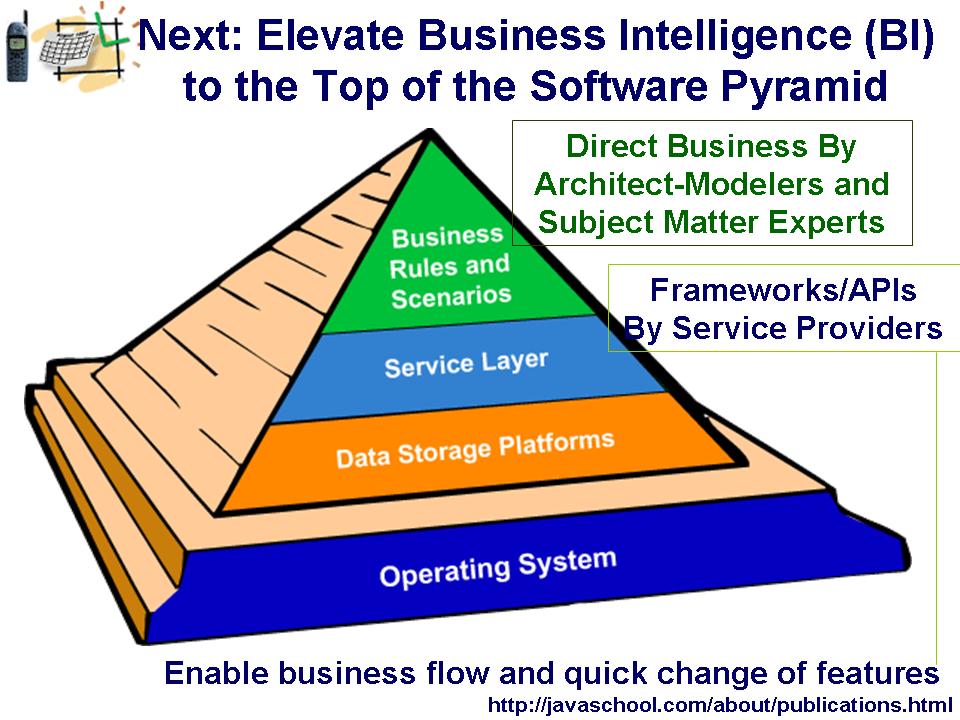
In knowledge-driven architecture (KDA), business rules and application scenarios are directly expressed in the knowledgebase in almost natural language and represent a thin application layer that drives the application. This architectural advance can allow an enterprise to shorten development time and produce smarter systems that can quickly accommodate themselves to rapid changes. (See Example)
This approach introduces a world of ontology and bridges best practices in software and knowledge engineering.
Knowledgebase vs. Database and Rules Engine
What is the difference between a knowledgebase and a database? A database is an empty vessel ready to be filled with any raw data. A rules engine is another empty vessel specialized to store rules in some proprietary format. A knowledgebase is different not only because it can represent data and rules all together, but because it is not just an empty container.
A knowledgebase comes full of well-organized data, facts, concepts, and rules that represent fundamental generic knowledge. A knowledgebase includes an inference engine that supports information integrity, and can help us in a decision-making process. That’s why a knowledgebase is more than just data storage or a search processor. The knowledgebase can serve us as a smart partner in multiple applications.
Very soon, we’ll find that the knowledgebase has become a commodity that successfully competes with the database in the data storage market. Some database vendors might already be looking for a path to make the transition. A knowledgebase can serve as a front-runner that can drastically simplify an interface for non-technical users, while traditional storage platforms can optimize back-end performance mechanisms in smart data storage markets.
Computers operate with data. We, human beings, operate with knowledge. At least, we would like to believe that this is true in most cases.
What is the difference between data and knowledge? In a very simplistic way, knowledge is well organized and related data. We can represent knowledge as multiple layers of data, where the next data layer can only come on top of existing data.
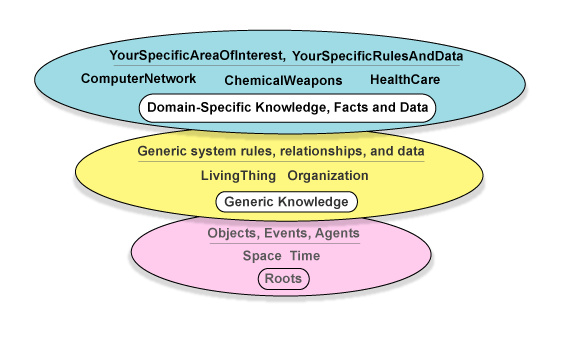
Fig.4. Knowledgebase layers
For example, I can tell you a new word, “Prevet”. You can only learn this word after I add that it means “Hello” in Russian. The learning happens when we establish a connection between this new word and existing data. There must be a background data layer to accept new information.
We, people, have many background layers. If you tell me a story about your neighbor I immediately know that the story is about a person, and that this person lives close to you.
Computers lack these layers of data today. For a computer, the word “neighbor” is just eight characters.
Yet, it is possible to collect multiple layers of fundamental data and code this data in multiple layers of a knowledgebase. Knowledge engineers are doing this work for us as you read these lines. The army of knowledge engineers will grow. We’ll join their trenches when we need to add our specific business domain knowledge to existing fundamental data.
The knowledge engine also includes powerful logical mechanisms, such as an inference engine. These mechanisms allow the knowledgebase to support data integrity and to find and resolve conflicting situations while taking into account multiple factors.
Thousands of concepts and relationships, which we take for granted and assume everyone knows, are moving into bits and bytes. Logical rules that we use every day are translated into inference engine algorithms. For example, an inference engine checks incoming data for conflicts with existing knowledge and rejects conflicting information. So far, computers cannot tolerate conflicting data. (This is another difference between machines and us.)
The knowledge layer that we add to systems brings us closer to the point where we can delegate more tasks (beyond inventory and order applications) to computers.
Ontology and
Predicate Logic vs. Boolean Logic
In our current software development process, we use the limited vocabulary of programming languages based on boolean logic and the limited (hierarchical) relationships of the object-oriented approach.
Ontology and Predicate Logic have unlimited vocabulary, which brings us closer to natural language and to multiple relationships, and therefore to real life.
We can express more complexity with fewer words.
Here is an example.
I express the simple idea “An Administrator can change member roles” in the Cyc Language [2].
(implies
(and
(hasMembershipIn ?USER ?GROUP)
(hasRole ?USER ?GROUP Admin)
(hasPrivilege ?USER ?GROUP ChangeMemberRoles)))
This might look a bit strange for a programmer, but we can read it like a poem:
If a user has membership in a group
And the user’s role is admin
This user has the privilege to change member roles.
This is readable, understandable, and ready for the knowledgebase.
No programming code or compiler is needed.
How is this possible? The knowledgebase (KB) already knows the basic concepts, like ‘member’ and ‘memberships’, as well as the relationships, like ‘hasRole’, ‘hasMembershipsIn’, etc. The knowledgebase is not an empty container like a DB, but is a smart partner with fundamental knowledge. We need only add our specifics to existing generic facts and rules.
Practical
implications and some implementation strategies
In the
image below, you can see a system implementation that has been written in Java
(a C# version would reuse most of this code.) The system components interpret
XML-based application scenarios, and interact with the knowledgebase,
presentation layer, and other services. In these systems, business rules and
scenarios retrieved from the knowledgebase can form an audio or video user
interface and can invoke existing services like document and business flow
processors, etc. Service invocations are implemented with Java (or C#)
reflection. There is also a "Distributed Network Communicator"
component (based on JXTA protocols) that allows systems to be engaged in a
collaborative knowledge framework [3].
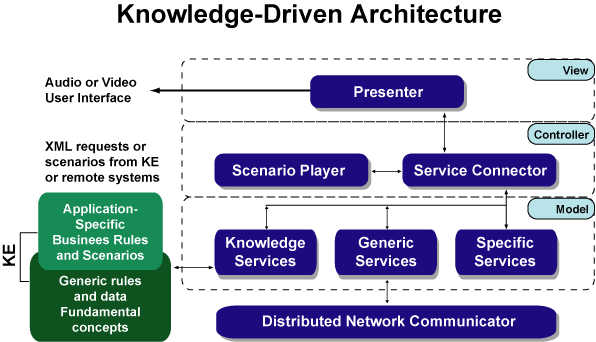
Fig.5.KDA
XML-based application scenarios
include both BPEL and ontology types of expressions. The ScenarioPlayer component interprets a subset of BPEL and
also allows applications to talk to a knowledgebase with predicate logics
(ontology expressions) and create adaptable rules on the fly. This capacity can
drastically improve the potential of software in pattern recognition and
decision making processes.
Does it mean that we will give up relational and XML data to switch to smarter platforms? This does not seem to be the case. XML has become a standard for internal (low-level) data representation for multiple platforms. Relational data are often built-upon this representation.
Data
vendors have developed great performance mechanisms that will benefit
higher-level systems. Knowledgebase-driven applications are relatively slow. To
boost performance of data intensive applications, the current implementation
(KDA container) can be integrated with existing data management products like the
IBM’s DB2 and WebSphere Application Server with the
process choreographer BPEL4WS-compliant environment.
Conclusion
The integration of software and knowledge engineering is arriving on the scene in much the same way as object-oriented programming did when it replaced structural programming. Here are some of the most promising applications of this new approach:
- Natural User Interface (NUI). Pattern recognition is applicable to images, voice, handwriting, and even translation from a foreign language. This makes a Natural User Interface (NUI), an interface selected by the user, a reality. You can type, use handwriting, or even speak with a foreign accent, and it will still be OK.
- Direct Business. Subject matter experts will get the keys to development, and can directly enter their requirements as business rules and scenarios. End users will be able to change business rules and scenarios at run-time without asking for an upgrade or new project development.
- Multiple factor resolution. When it comes to making a decision based on multiple factors, we have a hard time when the number of factors gets large. How many factors do you think you can handle? In such situations, we rarely find optimal or even good solutions. Applications powered by knowledge-driven architecture can help us here.
- Smart data storage. Non-technical people will be able to use smart data storage platforms based on knowledge-driven architecture, while traditional storage mechanisms, like Oracle, can optimize back-end performance.
- Common-sense applications. We can approach new tasks that require common-sense systems. Knowledge-driven architecture can accommodate such systems in a very affordable way.
- Accelerated development tools. Development tool vendors will bring a new wave of tools for technical and not-so-technical people.
- Distributed Knowledge Marketplace. Knowledgeable people tend to learn more and share their knowledge. Knowledge-powered systems will demonstrate similar behavior. Built-in to every Knowledge-Driven Architecture system, the distributed network communicator component can help connect the systems into distributed knowledge networks with simplified and more intuitive user-computer interaction. New ways to exchange and share knowledge and services will create markets that are distributed over the globe, and available to everyone who has privileges to contribute and consume data and services. New levels of collaboration will require new motivation and security mechanisms to enable distributed active knowledge networks.
- A new world of applications and
business markets.
References:
- Zhuk, Jeff, “Integration-Ready Architecture and Design. Software Engineering with XML, Java, .NET, Wireless, Speech, and Knowledge Technologies”, Cambridge University Press, 2004, ISBN 0521525837, http://javaschool.com/school/public/web/books
- Cyc Corporation, a leader in knowledge technologies, http://cyc.com
- The
session at Java One International Conference, 2004: Zhuk, Jeff, “Distributed Life in JXTA Knowledge
Networks”, http://www.jxta.org/JavaOne